library(tidyverse)
library(zoo)
library(sf)
library(tmap)
library(plotly)
options(scipen = 99)GDP/GVA regional gaps in the UK
Identifying regional gaps in GVA/GDP in the UK
We can get regional GVA/GDP data in a range of different flavours. Take a look at the page examining data from Beatty & Fothergill’s work on this, showing what difference choice of measure makes.
On this page, we’ll look at two GVA measures: GVA per hour worked and GVA per capita / per head of population. The code here compares South Yorkshire with the rest of the UK; it’s easy to adapt to other regions.
These two are a useful contrast for thinking about how interventions might change them, if we hope to improve productivity or output. For example, successfully moving people from inactivity into work (into most likely below average pay jobs) or creating new jobs that are below average productivity per hour, will lower the ‘GVA per hour’ number but increase GVA per capita.
[To do: interactive dropdowns for different regions, possibly in Shiny]
Let’s start with one of the most common measures of regional productivity, GVA per hour worked. Information on data sources is in the code comments, but note that the hourly work data comes from the Annual Population Survey and Labour Force Survey (see ‘measuring the data’ here at ONS). ONS say in their June 2023 analysis of this data:
“Output per hour worked is the preferred measure of labour productivity, as hours worked are a more precise measure of labour input than jobs.”
Also here:
“GVA per hour worked is considered a more comprehensive indicator of labour productivity and the preferred measure at subnational level. This is because GVA per filled job does not take into consideration regional labour market structures or different working patterns, such as the mix of part-time and full-time workers, industry structure and job shares.”
First, the libraries we’ll use (and setting scipen to avoid any scientific notation):
Then load in the data for both ITL2 and ITL3 regions:
#ONS link to the Excel sheets: https://www.ons.gov.uk/economy/grossdomesticproductgdp/datasets/regionalgrossdomesticproductallnutslevelregions
#Data folder name of downloaded Excel sheets (from which the CSVs below have been exported)
#itlproductivity.xlsx
perhourworked <- read_csv('data/misc/Table A4 Current Price unsmoothed GVA B per hour worked £ ITL2 and ITL3 subregions 2004 to 2021.csv') %>%
rename(ITL = `ITL level`, ITLcode = `ITL code`, region = `Region name`) %>%
filter(ITL == 'ITL2') %>%
pivot_longer(cols = `2004`:`2021`, names_to = 'year', values_to = 'gva') %>%
mutate(year = as.numeric(year))
#Repeat for ITL3
perhourworked.itl3 <- read_csv('data/misc/Table A4 Current Price unsmoothed GVA B per hour worked £ ITL2 and ITL3 subregions 2004 to 2021.csv') %>%
rename(ITL = `ITL level`, ITLcode = `ITL code`, region = `Region name`) %>%
filter(ITL == 'ITL3') %>%
pivot_longer(cols = `2004`:`2021`, names_to = 'year', values_to = 'gva') %>%
mutate(year = as.numeric(year))As the file names say, this is GVA per hour worked in current prices. That is, it’s the actual money amount for that specific ‘current’ year (2004 to 2021 in this data) - so it’s not inflation adjusted.
GVA/GDP data comes in either current prices (CP) or chained volume (CV) numbers. CV data has been inflation-adjusted so that change over time can be looked at - but the adjustment is done for each region separately, meaning that the difference in scale between places will be slightly off. (You can check this in e.g. the sector data by summing the CV values for regions and noting that it does not match the total for the larger geographies they’re a part of.)
In practice, this means it’s best to use current prices data to compare between places and chained volume / inflation adjusted numbers to look at how specific places’ GVA/GDP changes over time.
However, it is possible to examine change over time in the current prices data if we just examine relative change, either in how proportions change or - as the next code block does - in how the rank position of places changes.
The following code:
- Finds rank position of all places over time
- Takes a moving 3 year average of that rank to smooth a bit
- Labels different parts of the UK - North, South, London, South apart from London
- Makes an interactive plot of the rank change over time (comparing the years after coalition govt and most recent years before COVID) with South Yorkshire highlighted
#Rank to see which ITL2 changed position the most
perhourworked <- perhourworked %>%
group_by(year) %>%
mutate(rank = rank(gva))
#3 year smoothing
perhourworked <- perhourworked %>%
arrange(year) %>%
group_by(region) %>%
mutate(
movingav = rollapply(gva,3,mean,align='center',fill=NA),
rank_movingav = rollapply(rank,3,mean,align='center',fill=NA),
rank_movingav_7yr = rollapply(rank,7,mean,align='center',fill=NA)
)
#Picking out England and North etc...
#Via https://github.com/DanOlner/regionalGVAbyindustry
#Northern England
north <- perhourworked$region[grepl('Greater Manc|Merseyside|West Y|Cumbria|Cheshire|Lancashire|East Y|North Y|Tees|Northumb|South Y', perhourworked$region, ignore.case = T)] %>% unique
#South England
south <- perhourworked$region[!grepl('Greater Manc|Merseyside|West Y|Cumbria|Cheshire|Lancashire|East Y|North Y|Tees|Northumb|South Y|Scot|Highl|Wales|Ireland', perhourworked$region, ignore.case = T)] %>% unique
#South minus London
south.minus.london <- south[!grepl('london',south,ignore.case = T)]
#England!
england <- c(north,south)
#England minus London
england.minus.london <- england[!grepl('london',england,ignore.case = T)]
#UK minus London
uk.minus.london <- perhourworked$region[!grepl('london',perhourworked$region,ignore.case = T)] %>% unique
#Add those regions into the per hour worked data
perhourworked <- perhourworked %>%
mutate(ns_england_restofUK = case_when(
region %in% north ~ 'North England',
region %in% south ~ 'South Eng (inc. London)',
.default = 'Scot/Wales/NI'
))
perhourworked <- perhourworked %>%
mutate(ns_england_restofUK_londonseparate = case_when(
region %in% north ~ 'North England',
region %in% south.minus.london ~ 'South Eng (exc. London)',
grepl('london',region,ignore.case = T) ~ 'London',
.default = 'Scot/Wales/NI'
))
#And a category for 'UK minus London'
perhourworked <- perhourworked %>%
mutate(UK_minus_london = case_when(
grepl('london',region,ignore.case = T) ~ 'London',
.default = 'UK minus London'
))South Yorkshire GVA per hour: rank position change
Seeing how rank position of GVA per hour worked has changed at three points - South Yorkshire shown using triangles.
#Add marker for South Yorkshire
perhourworked <- perhourworked %>%
mutate(selectedregion = region == 'South Yorkshire')
#Plot: first coalition years to pre covid
p <- ggplot(perhourworked %>% filter(year %in% c(2006,2012,2018)), aes(x = factor(year), y = rank_movingav, group = region, color = factor(year))) +
geom_line(aes(group = region), color = "grey44") +
geom_point(aes(shape = selectedregion, size = selectedregion)) +
facet_wrap(vars(ns_england_restofUK_londonseparate), nrow = 1) +
ylab('rank (3 year average)') +
xlab('year (average centre)') +
guides(colour="none", shape = "none", size = "none") +
theme_bw() +
ggtitle("GVA per hour: ITL2 zones rank position over time, SY is triangle.")
ggplotly(p, tooltip = c('region','rank_movingav'))South Yorkshire GVA per hour worked: PERCENT GAP to other UK regions over time
This and the following plots show how far ahead or behind, in percentage terms, different regions and comparators are to South Yorkshire.
Lines above zero are x% larger than South Yorkshire.
For example: here, London has consistently 60%+ higher GVA per hour worked than South Yorkshire.
After the gap closed toward 2010, has opened up again and sloped up since. Average of UK minus London is ~17.7% in the most recent years in this data.
#WEIGHTED AVERAGES
#Using number of hours worked per ITL2
#Get hours worked per week total for ITL2
totalhoursperweek <- read_csv('data/misc/Productivity Hours Worked per Week ITL2 and ITL3 subregions constrained to ITL1 2004 2021.csv') %>%
rename(ITL = `ITL level`, ITLcode = `ITL code`, region = `Region name`) %>%
filter(ITL == 'ITL2') %>%
pivot_longer(cols = `2004`:`2021`, names_to = 'year', values_to = 'hours_per_week') %>%
mutate(year = as.numeric(year))
#And same for ITL3 regions
totalhoursperweek.itl3 <- read_csv('data/misc/Productivity Hours Worked per Week ITL2 and ITL3 subregions constrained to ITL1 2004 2021.csv') %>%
rename(ITL = `ITL level`, ITLcode = `ITL code`, region = `Region name`) %>%
filter(ITL == 'ITL3') %>%
pivot_longer(cols = `2004`:`2021`, names_to = 'year', values_to = 'hours_per_week') %>%
mutate(year = as.numeric(year))
perhourworked.withtotalhours <- perhourworked %>% filter(year == 2020) %>%
ungroup() %>%
left_join(
totalhoursperweek %>% filter(year == 2020) %>% select(region,hours_per_week),
by = 'region'
)
#UK weighted average INCLUDING London
weightedaverages.perhourworked.UK <- perhourworked.withtotalhours %>%
summarise(
sy = perhourworked %>% filter(year == 2020, region == 'South Yorkshire') %>% select(movingav) %>% pull,#put SY in there to directly compare
mean_gva_av3years_weighted = weighted.mean(movingav, hours_per_week, na.rm=T)#get weighted average by each ITL2 grouping
) %>%
mutate(
prop_diff = (mean_gva_av3years_weighted - sy)/sy
)
#UK weighted average EXCLUDING London (and comparing JUST to London)
weightedaverages.perhourworked.UKminuslondon <- perhourworked.withtotalhours %>%
group_by(UK_minus_london) %>% #group by "UK minus london" vs "london by itself"
summarise(
sy = perhourworked %>% filter(year == 2020, region == 'South Yorkshire') %>% select(movingav) %>% pull,#put SY in there to directly compare
mean_gva_av3years_weighted = weighted.mean(movingav, hours_per_week, na.rm=T)#get weighted average by each ITL2 grouping
) %>%
mutate(
prop_diff = (mean_gva_av3years_weighted - sy)/sy
)
#So SY would need to be ~17.7% more productive to match non London UK average
#Weighted averages, comparison to rest of North
weightedaverages.perhourworked.north <- perhourworked.withtotalhours %>%
group_by(ns_england_restofUK_londonseparate) %>% #group by "UK minus london" vs "london by itself"
summarise(
sy = perhourworked %>% filter(year == 2020, region == 'South Yorkshire') %>% select(movingav) %>% pull,
mean_gva_av3years_weighted = weighted.mean(movingav, hours_per_week, na.rm=T)#get weighted average by each ITL2 grouping
) %>%
mutate(
prop_diff = (mean_gva_av3years_weighted - sy)/sy
)
#Sanity check the weighted average manually, check with london
#TICK
chk <- perhourworked %>% filter(year == 2020) %>%
left_join(
totalhoursperweek %>% filter(year == 2020) %>% select(region,hours_per_week),
by = 'region'
) %>% filter(grepl('london',region,ignore.case = T)) %>%
ungroup() %>%
mutate(hours_per_week_normalised = hours_per_week / sum(hours_per_week)) %>%
mutate(
manualweightedav_weights = movingav * hours_per_week_normalised,
manualweightedav = sum(manualweightedav_weights)
)
#Selection... don't think we have an easy ITL2 East Mids match, will have to come back to...
mcas <- perhourworked.withtotalhours$region[grepl('South Y|Manc|West Y|West M|Tyne|Tees|West of Eng|North Y|Liverpool|East M', perhourworked.withtotalhours$region, ignore.case = T)] %>% unique
perhourworked.withtotalhours <- perhourworked %>%
ungroup() %>%
select(-c(movingav,rank_movingav,rank_movingav_7yr)) %>% #drop moving averages, redo after
left_join(
totalhoursperweek %>% select(region,hours_per_week,year),
by = c('region','year')
)
#Weighted averages
weightedaverages.perhourworked.UKminuslondon <- perhourworked.withtotalhours %>%
rename(region_grouping = UK_minus_london) %>%
group_by(region_grouping,year) %>%
summarise(
weighted_mean_gva = weighted.mean(gva, hours_per_week, na.rm=T)#get weighted average by each ITL2 grouping
) %>% #merge in SY values
left_join(perhourworked %>% filter(region == 'South Yorkshire') %>% ungroup() %>% select(year, SouthYorks_gva = gva), by = c('year')) %>%
mutate(
prop_diff = (weighted_mean_gva - SouthYorks_gva)/SouthYorks_gva,
prop_diff_3yrsmooth = rollapply(prop_diff,3,mean,align='center',fill=NA),
)
# ggplot(weightedaverages.perhourworked.UKminuslondon, aes(x = year, y = prop_diff_3yrsmooth * 100, colour = region_grouping)) +
# geom_line() +
# geom_point(size = 2) +
# coord_cartesian(ylim = c(0,80))
#For other groupings...
weightedaverages.perhourworked.regions <- perhourworked.withtotalhours %>%
rename(region_grouping = ns_england_restofUK_londonseparate) %>%
group_by(region_grouping,year) %>%
summarise(
weighted_mean_gva = weighted.mean(gva, hours_per_week, na.rm=T)#get weighted average by each ITL2 grouping
) %>% #merge in SY values
left_join(perhourworked %>% filter(region == 'South Yorkshire') %>% ungroup() %>% select(year, SouthYorks_gva = gva), by = c('year')) %>%
mutate(
prop_diff = (weighted_mean_gva - SouthYorks_gva)/SouthYorks_gva,
prop_diff_3yrsmooth = rollapply(prop_diff,3,mean,align='center',fill=NA),
)
#For MCA weighted av
weightedaverages.perhourworked.mcas <- perhourworked.withtotalhours %>%
mutate(region_grouping = ifelse(region %in% mcas[mcas!='South Yorkshire'], 'MCAs exc. SY','Other')) %>%
group_by(region_grouping,year) %>%
summarise(
weighted_mean_gva = weighted.mean(gva, hours_per_week, na.rm=T)#get weighted average by each ITL2 grouping
) %>% #merge in SY values
left_join(perhourworked %>% filter(region == 'South Yorkshire') %>% ungroup() %>% select(year, SouthYorks_gva = gva), by = c('year')) %>%
mutate(
prop_diff = (weighted_mean_gva - SouthYorks_gva)/SouthYorks_gva,
prop_diff_3yrsmooth = rollapply(prop_diff,3,mean,align='center',fill=NA),
)
#Join those three
weightedaverages.perhourworked.all <- bind_rows(
weightedaverages.perhourworked.UKminuslondon,
weightedaverages.perhourworked.regions,
weightedaverages.perhourworked.mcas %>% filter(region_grouping!='Other')
)
#Do factor order here so can apply also elsewhere
weightedaverages.perhourworked.all$region_grouping <- fct_reorder(weightedaverages.perhourworked.all$region_grouping,weightedaverages.perhourworked.all$prop_diff_3yrsmooth, .desc=T)
ggplot(weightedaverages.perhourworked.all, aes(x = year, y = prop_diff_3yrsmooth * 100, colour = region_grouping,prop_diff_3yrsmooth)) +
# ggplot(weightedaverages.perhourworked.all, aes(x = year, y = prop_diff_3yrsmooth * 100, colour = fct_reorder(region_grouping,prop_diff_3yrsmooth, .desc=T))) +
geom_line() +
geom_point(size = 2) +
coord_cartesian(ylim = c(0,72)) +
scale_color_brewer(palette = 'Paired', direction = -1) +
ylab("South Yorks percent difference of... (3 year average)") +
theme(legend.title=element_blank()) +
ggtitle("South Yorkshire GVA per hour worked: percent difference of other regions\n(e.g. South England is ~18 to 20% larger GVA per hour worked)")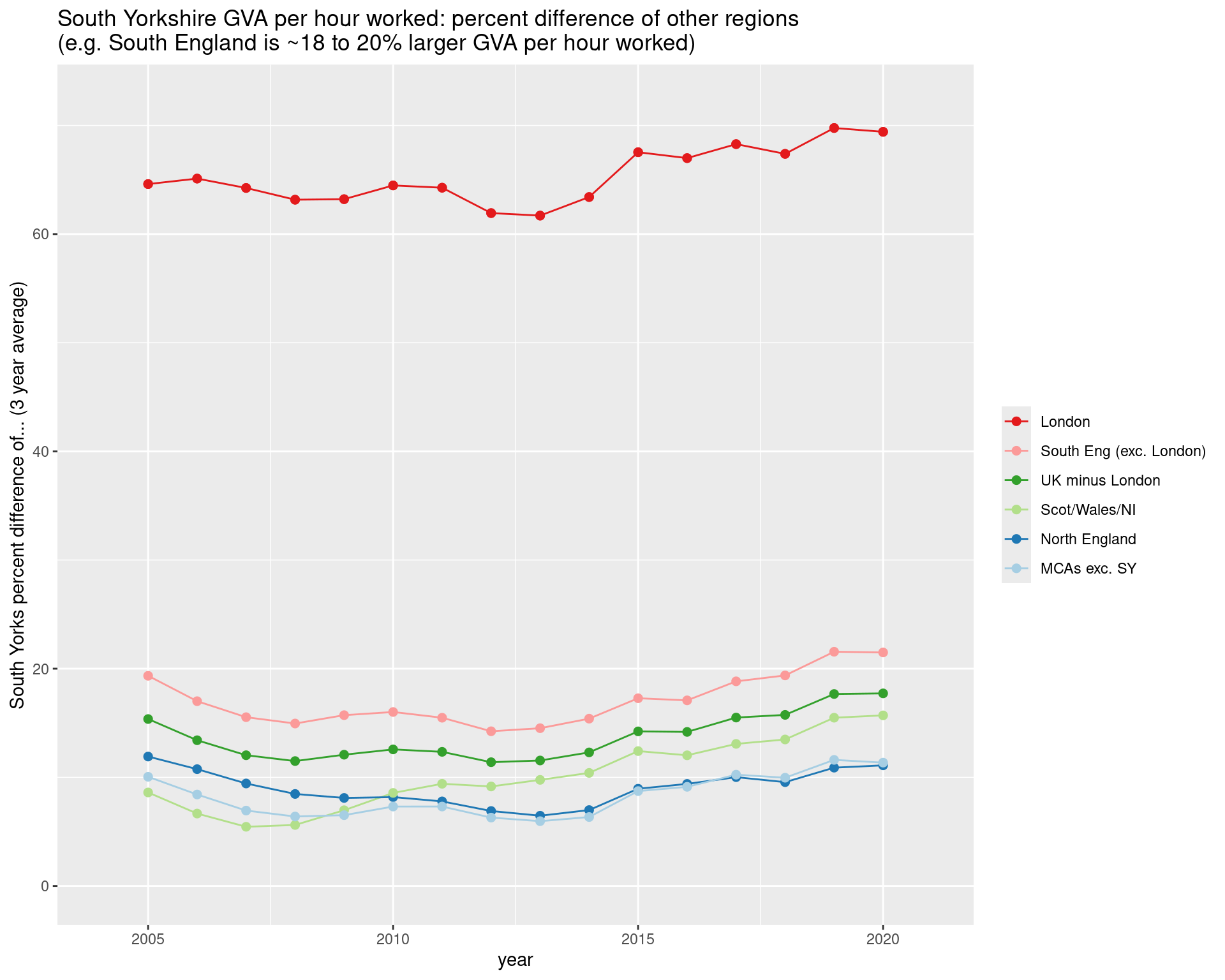
Same slide minus London…
Removing London, as it’s just an outlier. Setting the scale so it’s fixed, for comparing to GVA per capita in the next slide.
ggplot(weightedaverages.perhourworked.all %>% filter(region_grouping!='London'), aes(x = year, y = prop_diff_3yrsmooth * 100, colour = region_grouping)) +
# ggplot(weightedaverages.perhourworked.all %>% filter(region_grouping!='London'), aes(x = year, y = prop_diff_3yrsmooth * 100, colour = fct_reorder(region_grouping,prop_diff_3yrsmooth, .desc=T))) +
geom_line() +
geom_point(size = 2) +
coord_cartesian(ylim = c(0,42)) +
geom_hline(yintercept = 0, alpha = 0.2, size = 2) +
scale_color_brewer(palette = 'Paired', direction = -1) +
ylab("South Yorks percent difference of... (3 year average)") +
theme(legend.title=element_blank()) +
ggtitle("South Yorkshire GVA per hour worked: percent difference of other regions\n(e.g. South England is ~18 to 20% larger GVA per hour worked)")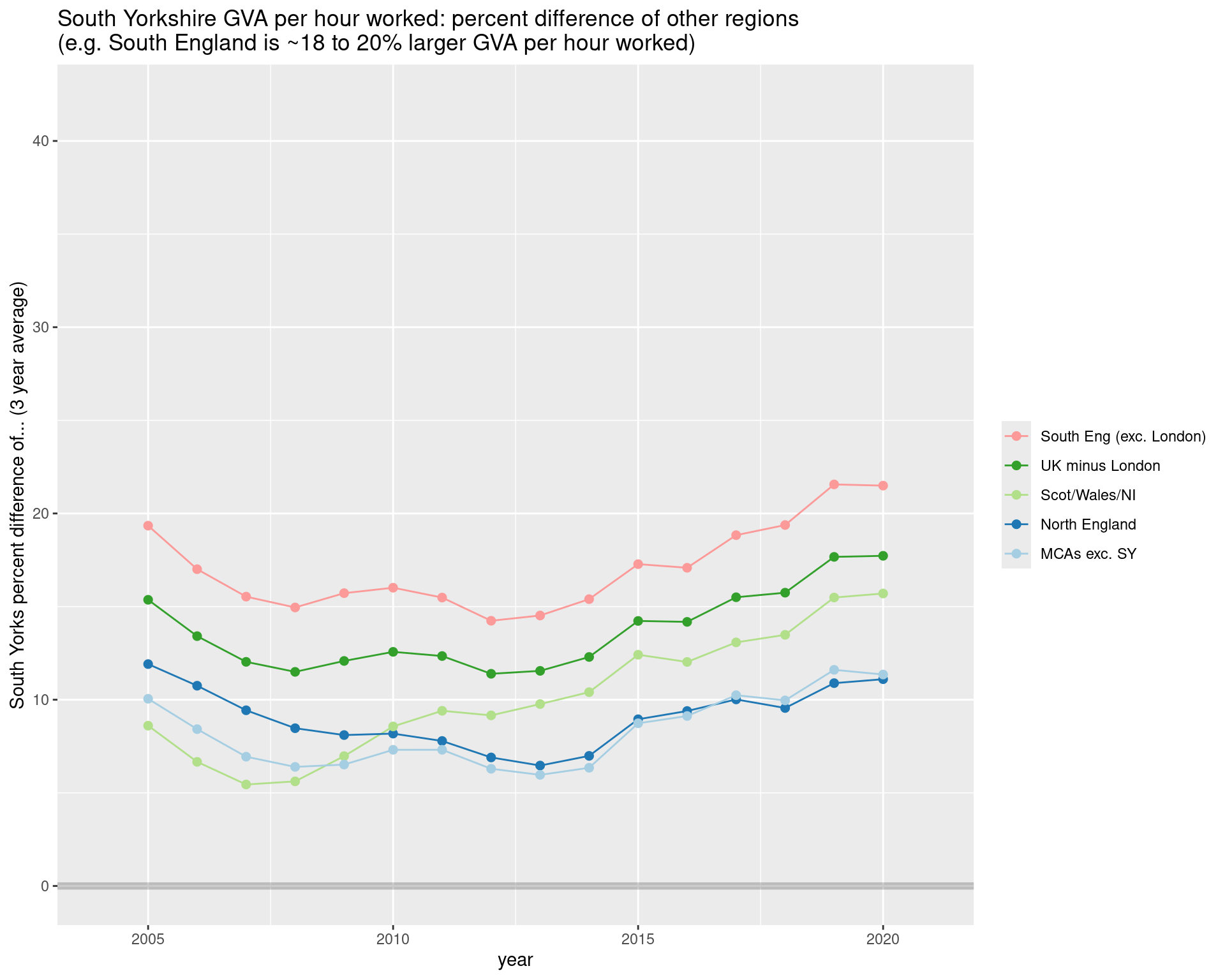
GVA PER CAPITA: South Yorkshire
GVA per head of resident population
This data goes back further, to 1998.
Similar opening gap to other regions, but in the few (COVID?) years, that gap in the per capita numbers has begun to close again.
#Get population numbers for per person figures
#From regionalgrossvalueaddedbalancedbyindustryandallitlregions.xlsx
#ONS mid year population estimates
#Table 6 (not sure where they got consistent ITL2 geogs from...)
#NOTE: UNCERTAINTY ISSUES IN LATEST DATA, DON'T USE FOR NOW. SEE ORIG EXCEL:
# personcounts <- read_csv('data/misc/Table 6 Total resident population numbers persons Apr2024.csv') %>%
personcounts <- read_csv('data/misc/Table 6 Total resident population numbers persons.csv') %>%
rename(ITLcode = `ITL code`, region = `Region name`) %>%
filter(ITL == 'ITL2') %>%
pivot_longer(cols = `1998`:`2021`, names_to = 'year', values_to = 'personcount') %>%
mutate(year = as.numeric(year))
#Total GVA in current basic prices from the same source
# gva.cp <- read_csv('data/misc/Table 1 GVA balanced at current basic prices millions Apr2024.csv') %>%
gva.cp <- read_csv('data/misc/Table 1 GVA balanced at current basic prices millions.csv') %>%
rename(ITLcode = `ITL code`, region = `Region name`) %>%
filter(ITL == 'ITL2') %>%
pivot_longer(cols = `1998`:`2021`, names_to = 'year', values_to = 'gva') %>%
mutate(year = as.numeric(year))
#Add person counts in to get GVA per capita
#Check link match... tick
# table(personcounts$region %in% gva.cp$region)
gva.cp <- gva.cp %>%
left_join(
personcounts %>% select(region, year, personcount),
by = c('region','year')
) %>%
mutate(
gva_per_capita = (gva / personcount) * 1000000
)
#Add in region labels as before
gva.cp <- gva.cp %>%
mutate(ns_england_restofUK = case_when(
region %in% north ~ 'North England',
region %in% south ~ 'South Eng (inc. London)',
.default = 'Scot/Wales/NI'
))
#Check full match
# table(gva.cp$ns_england_restofUK, useNA = 'always')
gva.cp <- gva.cp %>%
mutate(ns_england_restofUK_londonseparate = case_when(
region %in% north ~ 'North England',
region %in% south.minus.london ~ 'South Eng (exc. London)',
grepl('london',region,ignore.case = T) ~ 'London',
.default = 'Scot/Wales/NI'
))
# table(gva.cp$ns_england_restofUK_londonseparate, useNA = 'always')
#And a category for 'UK minus London'
gva.cp <- gva.cp %>%
mutate(UK_minus_london = case_when(
grepl('london',region,ignore.case = T) ~ 'London',
.default = 'UK minus London'
))
# table(gva.cp$UK_minus_london, useNA = 'always')
#Regions weighted averages
weightedaverages.gva.cp.regions <- gva.cp %>%
rename(region_grouping = ns_england_restofUK_londonseparate) %>%
group_by(region_grouping,year) %>%
summarise(
weighted_mean_gva = weighted.mean(gva_per_capita, personcount, na.rm=T)#get weighted average by each ITL2 grouping
) %>% #merge in SY values
left_join(gva.cp %>% filter(region == 'South Yorkshire') %>% ungroup() %>% select(year, SY_gva = gva_per_capita), by = c('year'))
#Repeat for UK minus London av
weightedaverages.gva.cp.ukminusLondon <- gva.cp %>%
rename(region_grouping = UK_minus_london) %>%
group_by(region_grouping,year) %>%
summarise(
weighted_mean_gva = weighted.mean(gva_per_capita, personcount, na.rm=T)#get weighted average by each ITL2 grouping
) %>% #merge in SY values
left_join(gva.cp %>% filter(region == 'South Yorkshire') %>% ungroup() %>% select(year, SY_gva = gva_per_capita), by = c('year'))
#Repeat for MCA average minus SY
weightedaverages.gva.cp.mcas <- gva.cp %>%
mutate(region_grouping = ifelse(region %in% mcas[mcas!='South Yorkshire'], 'MCAs exc. SY','Other')) %>%
group_by(region_grouping,year) %>%
summarise(
weighted_mean_gva = weighted.mean(gva_per_capita, personcount, na.rm=T)#get weighted average by each ITL2 grouping
) %>% #merge in SY values
left_join(gva.cp %>% filter(region == 'South Yorkshire') %>% ungroup() %>% select(year, SY_gva = gva_per_capita), by = c('year'))
#Append those three
weightedavs.gva.cp <-
bind_rows(
weightedaverages.gva.cp.regions,
weightedaverages.gva.cp.ukminusLondon %>% filter(region_grouping!='London'),#Got London in the previous one
weightedaverages.gva.cp.mcas %>% filter(region_grouping!='Other')
)
#Smooth
weightedavs.gva.cp <- weightedavs.gva.cp %>%
mutate(
prop_diff = (weighted_mean_gva - SY_gva)/SY_gva
) %>%
arrange(year) %>%
group_by(region_grouping) %>%
mutate(
prop_diff_3yrsmooth = rollapply(prop_diff,3,mean,align='center',fill=NA),
prop_diff_5yrsmooth = rollapply(prop_diff,5,mean,align='center',fill=NA),
)
#Apply same factor order as previous
weightedavs.gva.cp$region_grouping <- factor(weightedavs.gva.cp$region_grouping, levels = levels(weightedaverages.perhourworked.all$region_grouping))
#Plain prop diff in per capita numbers looks smoothed already / isn't reliant on small samples?
# ggplot(weightedavs.gva.cp, aes(x = year, y = prop_diff * 100, colour = region_grouping)) +
ggplot(weightedavs.gva.cp %>% filter(region_grouping!='London'), aes(x = year, y = prop_diff * 100, colour = region_grouping)) +
# ggplot(weightedavs.gva.cp %>% filter(region_grouping!='London'), aes(x = year, y = prop_diff * 100, colour = fct_reorder(region_grouping, prop_diff, .desc = T))) +
geom_line() +
geom_point(size = 2) +
coord_cartesian(ylim = c(0,42)) +
geom_hline(yintercept = 0, alpha = 0.2, size = 2) +
scale_color_brewer(palette = 'Paired', direction = -1) +
ylab("Percent difference of... ") +
theme(legend.title=element_blank()) +
ggtitle("GVA per capita: South Yorkshire % difference of regions\nIncluding av. of MCA list")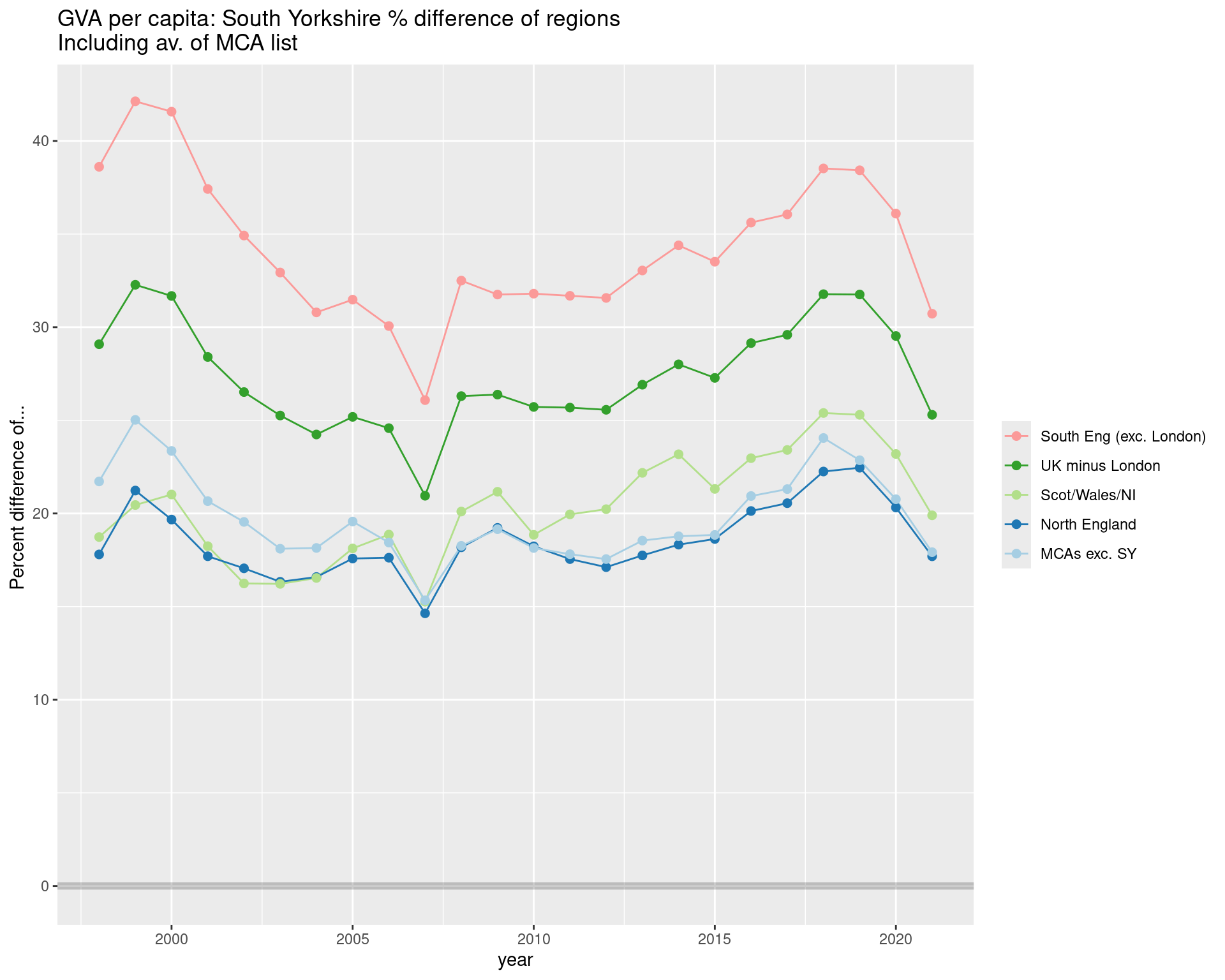
GVA Per HOUR WORKED: South Yorkshire vs other MCAs
South Yorkshire’s per hour worked has remained consistently below this selection of other MCAs - though the scale of the gap varies a lot depending on MCA.
#COMPARE TO SELECTION OF ITL2 ZONES / OTHER MCAs
#VERSION TO DIRECTLY COMPARE SY TO OTHER MCAS
#List of ITL2
# unique(perhourworked.withtotalhours$region)
#Selection... don't think we have an easy ITL2 East Mids match, will have to come back to...
mcas <- perhourworked.withtotalhours$region[grepl('South Y|Manc|West Y|West M|Tyne|Tees|West of Eng|North Y|Liverpool|East M', perhourworked.withtotalhours$region, ignore.case = T)] %>% unique
#MCA to get proportion gaps to others
comparator = perhourworked.withtotalhours$region[grepl('South Y', perhourworked.withtotalhours$region, ignore.case = T)] %>% unique
# comparator = perhourworked.withtotalhours$region[grepl('Greater M', perhourworked.withtotalhours$region, ignore.case = T)] %>% unique
mcacompare <- perhourworked.withtotalhours %>%
select(region, year, gva) %>%
filter(region %in% mcas[mcas!=comparator]) %>%
left_join(
perhourworked.withtotalhours %>%
filter(region ==comparator) %>%
select(year, comp_gva = gva),
by = 'year'
) %>%
mutate(prop_diff = (gva - comp_gva)/comp_gva) %>%
group_by(region) %>%
mutate(
prop_diff_3yrsmooth = rollapply(prop_diff,3,mean,align='center',fill=NA),
prop_diff_5yrsmooth = rollapply(prop_diff,5,mean,align='center',fill=NA),
)
#Factor here to apply to the next plot
mcacompare$region <- fct_reorder(mcacompare$region,mcacompare$prop_diff_3yrsmooth, .desc=T)
ggplot(mcacompare, aes(x = year, y = prop_diff_3yrsmooth * 100, colour = region)) +
# ggplot(mcacompare, aes(x = year, y = prop_diff_3yrsmooth * 100, colour = fct_reorder(region, prop_diff_3yrsmooth, .desc=T))) +
# ggplot(corecompare, aes(x = year, y = prop_diff * 100, colour = fct_reorder(region, prop_diff))) +
geom_line() +
geom_point(size = 2) +
coord_cartesian(ylim = c(-8,37)) +
geom_hline(yintercept = 0, alpha = 0.2, size = 2) +
scale_color_brewer(palette = 'Paired', direction = -1) +
ylab("South Yorks percent difference of... (3 year average)") +
theme(legend.title=element_blank()) +
ggtitle("South Yorkshire GVA per hour worked: % difference of other MCAs\n(e.g. GM has 10-14% higher GVA per hour worked than SY)")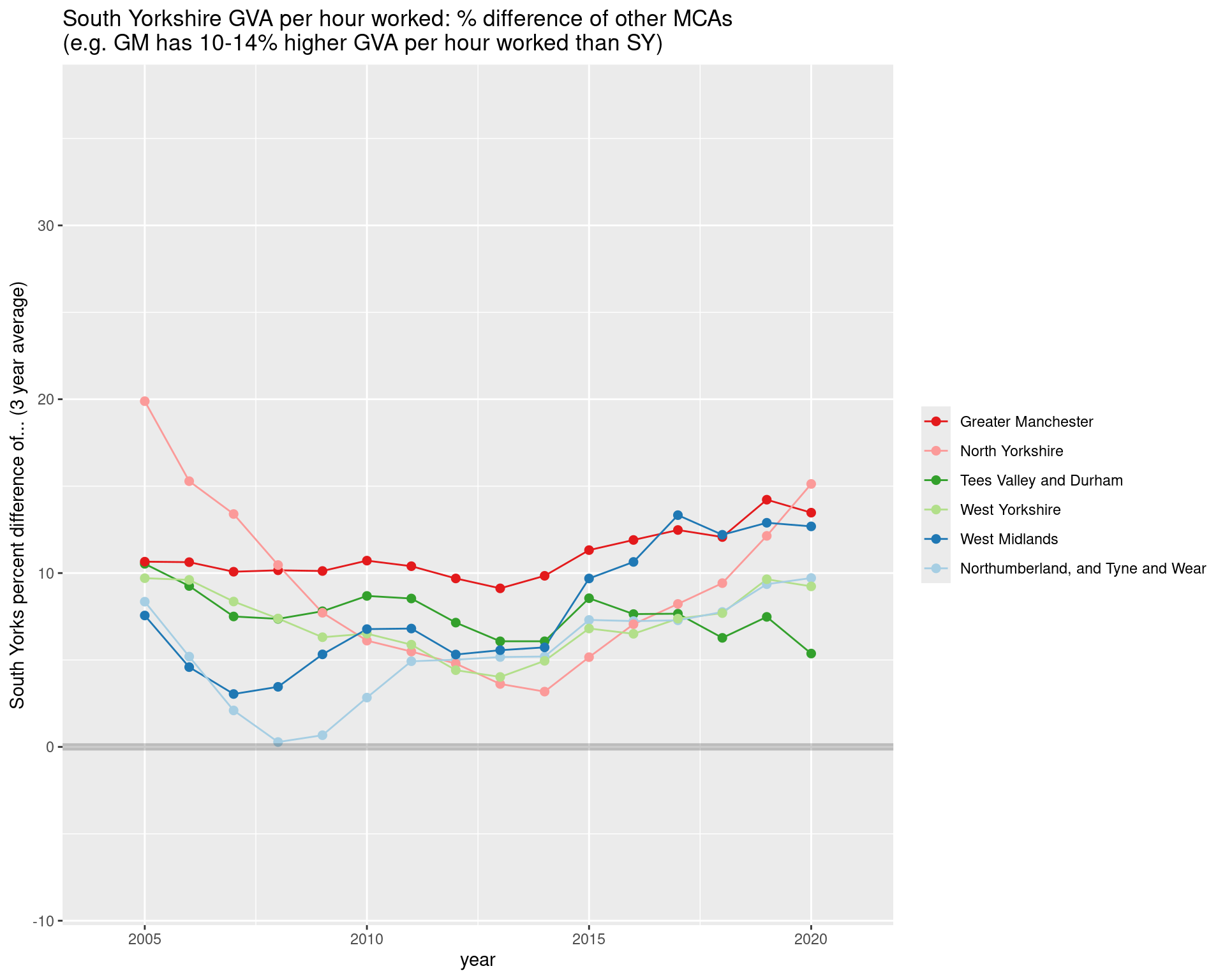
GVA Per CAPITA: South Yorkshire vs other MCAs
Looking at GVA per capita on the same scale, the recent closing gap is again visible.
Also, South Yorkshire is comparable to Tees Valley/Durham and has pulled ahead slightly since 2011.
#COMPARE THE MCAS DIRECTLY
#MCA to get proportion gaps to others
comparator = perhourworked.withtotalhours$region[grepl('South Y', perhourworked.withtotalhours$region, ignore.case = T)] %>% unique
# comparator = perhourworked.withtotalhours$region[grepl('Greater M', perhourworked.withtotalhours$region, ignore.case = T)] %>% unique
mcacompare.percapita <- gva.cp %>%
select(region, year, gva_per_capita) %>%
filter(region %in% mcas[mcas!=comparator]) %>%
left_join(
gva.cp %>%
ungroup() %>%
filter(region == comparator) %>%
select(year, SY_gva = gva_per_capita),
by = 'year'
) %>%
mutate(prop_diff = (gva_per_capita - SY_gva)/SY_gva) %>%
group_by(region) %>%
mutate(
prop_diff_3yrsmooth = rollapply(prop_diff,3,mean,align='center',fill=NA),
prop_diff_5yrsmooth = rollapply(prop_diff,5,mean,align='center',fill=NA),
)
#Get factor order from previous plot
mcacompare.percapita$region <- factor(mcacompare.percapita$region, levels = levels(mcacompare$region))
ggplot(mcacompare.percapita, aes(x = year, y = prop_diff * 100, colour = region, prop_diff, .desc = T)) +
# ggplot(mcacompare.percapita, aes(x = year, y = prop_diff * 100, colour = fct_reorder(region, prop_diff, .desc = T))) +
geom_line() +
geom_point(size = 2) +
coord_cartesian(ylim = c(-8,37)) +
geom_hline(yintercept = 0, alpha = 0.2, size = 2) +
scale_color_brewer(palette = 'Paired', direction = -1) +
ylab("Percent difference of... ") +
theme(legend.title=element_blank()) +
ggtitle("GVA per capita: South Yorkshire % difference of regions\nincluding av. of MCA list")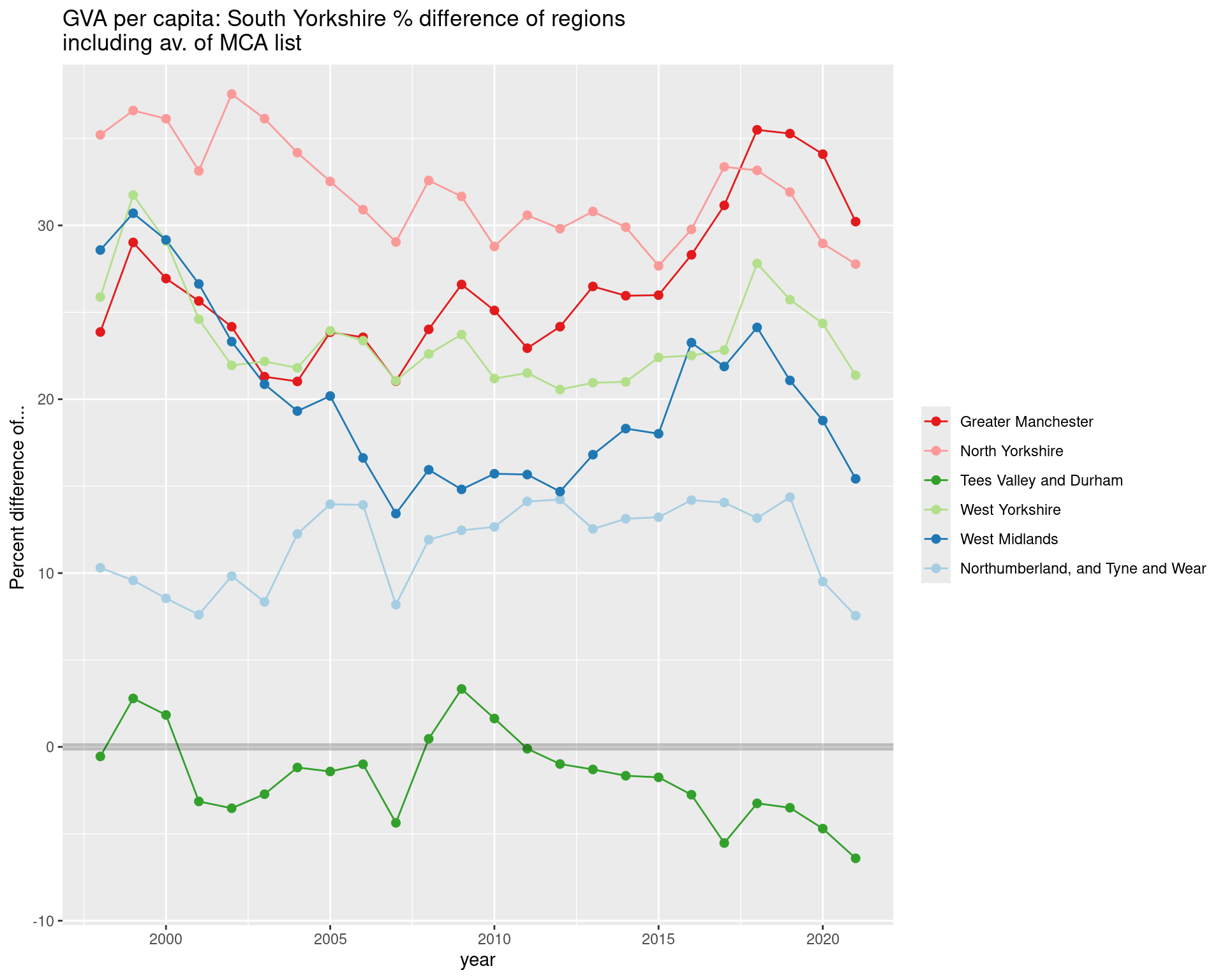
SHEFFIELD AND BARNSLEY / DONCASTER / ROTHERHAM
GVA per HOUR WORKED: Separating Sheffield from Barnsley / Doncaster / Rotherham:
Separating Sheffield from Barnsley, Doncaster and Rotherham shows how the GVA gaps split across South Yorkshire.
Barnsley, Doncaster and Rotherham average around a 20% gap. Sheffield’s gap to the rest of the UK minus London has shifted between 5 to 10%.
The overall pattern is the same - an increasing gap in recent years - but Sheffield does seem now to be closing the gap, and was briefly ahead of the rest of the North in 2012-2013 here.
#Add the ITL2 code lookup to ITL3 data
perhourworked.itl3 <- perhourworked.itl3 %>%
mutate(
ITL2code = str_sub(perhourworked.itl3$ITLcode,1,-2)
)
#Merge in region labels from the ITL2 data
perhourworked.itl3 <- perhourworked.itl3 %>%
left_join(
perhourworked %>% ungroup() %>% distinct(ITLcode, ns_england_restofUK, ns_england_restofUK_londonseparate,UK_minus_london) %>% select(ITL2code = ITLcode, ns_england_restofUK, ns_england_restofUK_londonseparate,UK_minus_london),
by = 'ITL2code'
)
corecities <- perhourworked.itl3$region[grepl(x = perhourworked.itl3$region, pattern = 'sheffield|Belfast|Birmingham|Bristol|Cardiff|Glasgow|Leeds|Liverpool|Manchester|Tyne|Nottingham', ignore.case = T)] %>% unique
#Yes, all in there, need to remove a few...
corecities <- corecities[!grepl(x = corecities, pattern = 'Greater|shire', ignore.case = T)]
corecities <- corecities[order(corecities)]
perhourworked.itl3 <- perhourworked.itl3 %>%
mutate(
core_cities = ifelse(region %in% corecities, 'Core city', 'Other'),
core_cities_minus_sheffield = ifelse(region %in% corecities[corecities!='Sheffield'],'Core city (exc. Sheffield)','Other')#without sheffield, so not including in weighted average
)
#Check region match... tick
# table(perhourworked.itl3$region %in% totalhoursperweek.itl3$region)
#Join
perhourworked.withtotalhours.itl3 <- perhourworked.itl3 %>%
ungroup() %>%
# select(-c(movingav,rank_movingav,rank_movingav_7yr)) %>% #drop moving averages, redo after
left_join(
totalhoursperweek.itl3 %>% select(region,hours_per_week,year),
by = c('region','year')
)
#For other groupings...
weightedaverages.perhourworked.itl3.regions <- perhourworked.withtotalhours.itl3 %>%
rename(region_grouping = ns_england_restofUK_londonseparate) %>%
group_by(region_grouping,year) %>%
summarise(
weighted_mean_gva = weighted.mean(gva, hours_per_week, na.rm=T)#get weighted average by each ITL2 grouping
) %>% #merge in SY values
left_join(perhourworked.itl3 %>% filter(region == 'Sheffield') %>% ungroup() %>% select(year, Sheffield_gva = gva), by = c('year')) %>%
left_join(perhourworked.itl3 %>% filter(grepl(x = region, pattern = 'Barnsley', ignore.case = T)) %>% ungroup() %>% select(year, BDR_gva = gva), by = c('year'))
#Repeat for UK minus London
weightedaverages.perhourworked.itl3.UKminusLondon <- perhourworked.withtotalhours.itl3 %>%
rename(region_grouping = UK_minus_london) %>%
group_by(region_grouping,year) %>%
summarise(
weighted_mean_gva = weighted.mean(gva, hours_per_week, na.rm=T)#get weighted average by each ITL2 grouping
) %>% #merge in SY values
left_join(perhourworked.itl3 %>% filter(region == 'Sheffield') %>% ungroup() %>% select(year, Sheffield_gva = gva), by = c('year')) %>%
left_join(perhourworked.itl3 %>% filter(grepl(x = region, pattern = 'Barnsley', ignore.case = T)) %>% ungroup() %>% select(year, BDR_gva = gva), by = c('year'))
#Repeat for core cities exc Sheffield
weightedaverages.perhourworked.itl3.cores <- perhourworked.withtotalhours.itl3 %>%
rename(region_grouping = core_cities_minus_sheffield) %>%
group_by(region_grouping,year) %>%
summarise(
weighted_mean_gva = weighted.mean(gva, hours_per_week, na.rm=T)#get weighted average by each ITL2 grouping
) %>% #merge in SY values
left_join(perhourworked.itl3 %>% filter(region == 'Sheffield') %>% ungroup() %>% select(year, Sheffield_gva = gva), by = c('year')) %>%
left_join(perhourworked.itl3 %>% filter(grepl(x = region, pattern = 'Barnsley', ignore.case = T)) %>% ungroup() %>% select(year, BDR_gva = gva), by = c('year'))
#Append those two
weightedavs.itl3 <- bind_rows(
weightedaverages.perhourworked.itl3.regions,
weightedaverages.perhourworked.itl3.UKminusLondon %>% filter(region_grouping!='London'),#London already in .regions
weightedaverages.perhourworked.itl3.cores %>% filter(region_grouping!='Other')
)
#Make Sheffield and BDR gva long, and find proportion diffs
weightedavs.itl3 <- weightedavs.itl3 %>%
pivot_longer(cols = Sheffield_gva:BDR_gva, names_to = 'place', values_to = 'gva') %>%
mutate(
prop_diff = (weighted_mean_gva - gva)/gva
) %>%
arrange(year) %>%
group_by(region_grouping,place) %>%
mutate(
prop_diff_3yrsmooth = rollapply(prop_diff,3,mean,align='center',fill=NA),
prop_diff_5yrsmooth = rollapply(prop_diff,5,mean,align='center',fill=NA),
)
#Keep factor order for next plot
weightedavs.itl3$region_grouping <- fct_reorder(weightedavs.itl3$region_grouping, weightedavs.itl3$prop_diff_3yrsmooth, .desc=T)
ggplot(weightedavs.itl3 %>% filter(region_grouping!='London'), aes(x = year, y = prop_diff_3yrsmooth * 100, colour = region_grouping)) +
# ggplot(weightedavs.itl3 %>% filter(region_grouping!='London'), aes(x = year, y = prop_diff_3yrsmooth * 100, colour = fct_reorder(region_grouping, prop_diff_3yrsmooth, .desc=T))) +
geom_line() +
geom_point(size = 2) +
coord_cartesian(ylim = c(-5,82)) +
geom_hline(yintercept = 0, alpha = 0.2, size = 2) +
facet_wrap(~place) +
scale_color_brewer(palette = 'Paired', direction = -1) +
ylab("Percent difference of... (3 year average)") +
theme(legend.title=element_blank()) +
ggtitle("Sheffield vs Barnsley/Doncaster/Rotherham\nGVA per hour worked: % difference of other regions.")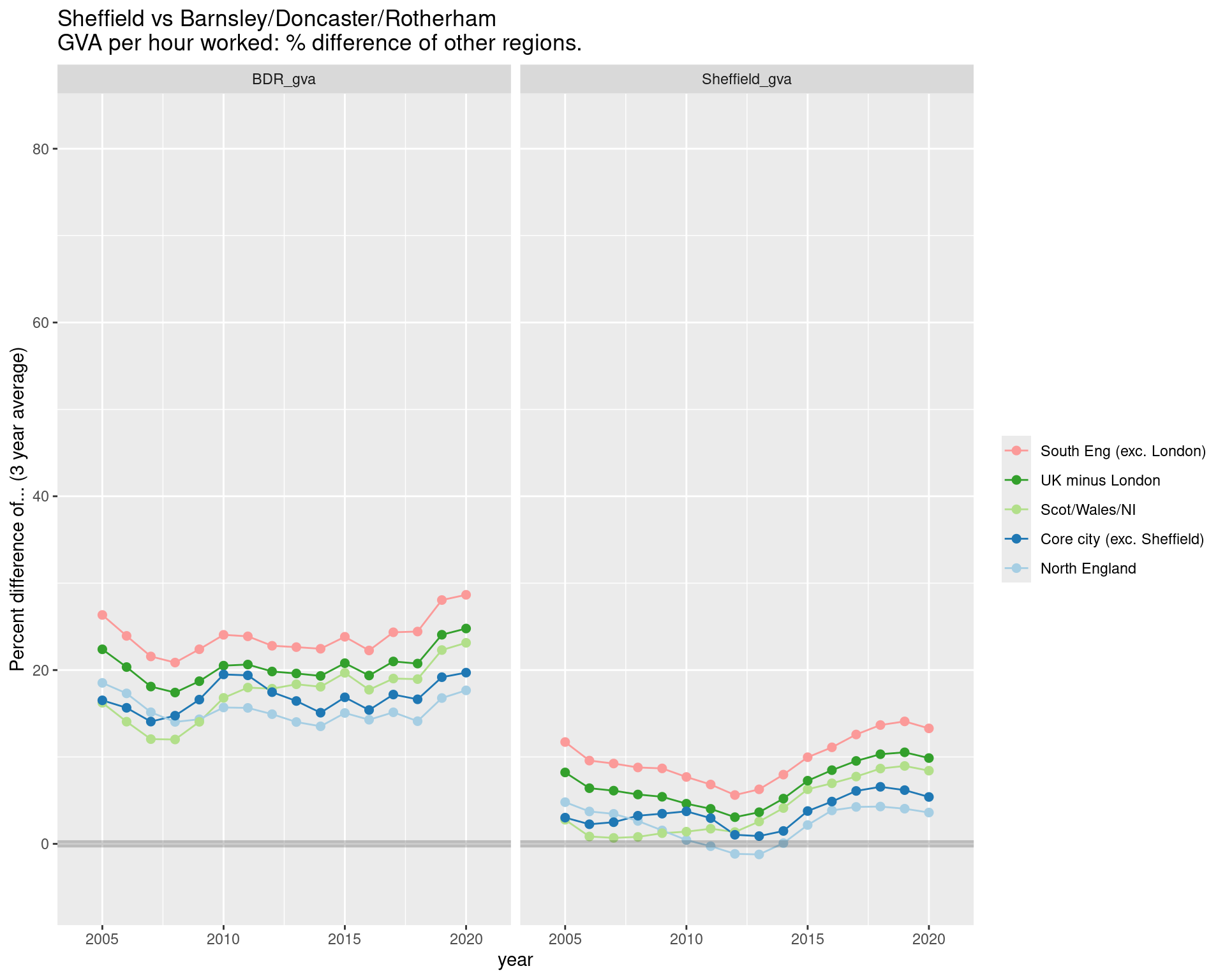
GVA PER CAPITA: Sheffield and Barnsley / Doncaster / Rotherham
Keeping the same scale for GVA PER CAPITA shows the same difference between Sheffield and BDR, but a different pattern of change over time, with Sheffield appearing to close the gap in more recent years.
Note also: the weighted average GVA per capita for the ‘core cities’ has the largest gap to both here. This is likely due to the dual effect of larger numbers of commuters in other core cities, and parallel lower resident populations increasing the ‘per capita’ GVA averages there (but needs more digging).
#Get population numbers for per person figures
#From regionalgrossvalueaddedbalancedbyindustryandallitlregions.xlsx
#ONS mid year population estimates
#Table 6 (not sure where they got consistent ITL2 geogs from...)
# personcounts.itl3 <- read_csv('data/misc/Table 6 Total resident population numbers persons Apr2024.csv') %>%
personcounts.itl3 <- read_csv('data/misc/Table 6 Total resident population numbers persons.csv') %>%
rename(ITLcode = `ITL code`, region = `Region name`) %>%
filter(ITL == 'ITL3') %>%
pivot_longer(cols = `1998`:`2021`, names_to = 'year', values_to = 'personcount') %>%
mutate(year = as.numeric(year))
#Total GVA in current basic prices from the same source
# gva.cp.itl3 <- read_csv('data/misc/Table 1 GVA balanced at current basic prices millions Apr2024.csv') %>%
gva.cp.itl3 <- read_csv('data/misc/Table 1 GVA balanced at current basic prices millions.csv') %>%
rename(ITLcode = `ITL code`, region = `Region name`) %>%
filter(ITL == 'ITL3') %>%
pivot_longer(cols = `1998`:`2021`, names_to = 'year', values_to = 'gva') %>%
mutate(year = as.numeric(year))
#Add person counts in to get GVA per capita
#Check link match... tick
# table(personcounts.itl3$region %in% gva.cp.itl3$region)
gva.cp.itl3 <- gva.cp.itl3 %>%
left_join(
personcounts.itl3 %>% select(region, year, personcount),
by = c('region','year')
) %>%
mutate(
gva_per_capita = (gva / personcount) * 1000000
)
#Use matching part ITL2 code to add region labels in
gva.cp.itl3 <- gva.cp.itl3 %>%
mutate(
ITL2code = str_sub(gva.cp.itl3$ITLcode,1,-2)
)
#Merge in region labels from the ITL2 data
gva.cp.itl3 <- gva.cp.itl3 %>%
left_join(
gva.cp %>% ungroup() %>% distinct(ITLcode, ns_england_restofUK, ns_england_restofUK_londonseparate, UK_minus_london) %>% select(ITL2code = ITLcode, ns_england_restofUK, ns_england_restofUK_londonseparate, UK_minus_london),
by = 'ITL2code'
)
#Add in an extra one for the shortlist of 11 'core cities'
#Belfast, Birmingham, Bristol, Cardiff, Glasgow, Leeds, Liverpool, Manchester, Newcastle, Nottingham, Sheffield
#https://www.corecities.com/about-us/what-core-cities-uk
gva.cp.itl3 <- gva.cp.itl3 %>%
mutate(
core_cities = ifelse(region %in% corecities, 'Core city', 'Other'),
core_cities_minus_sheffield = ifelse(region %in% corecities[corecities!='Sheffield'],'Core city (exc. Sheffield)','Other')#without sheffield, so not including in weighted average
)
#For region grouping... Weight averages by population
weightedaverages.gva.cp.itl3.regions <- gva.cp.itl3 %>%
rename(region_grouping = ns_england_restofUK_londonseparate) %>%
group_by(region_grouping,year) %>%
summarise(
weighted_mean_gva = weighted.mean(gva_per_capita, personcount, na.rm=T)#get weighted average by each ITL2 grouping
) %>% #merge in SY values
left_join(gva.cp.itl3 %>% filter(region == 'Sheffield') %>% ungroup() %>% select(year, Sheffield_gva = gva_per_capita), by = c('year')) %>%
left_join(gva.cp.itl3 %>% filter(grepl(x = region, pattern = 'Barnsley', ignore.case = T)) %>% ungroup() %>% select(year, BDR_gva = gva_per_capita), by = c('year'))
#repeat for UK minus London
weightedaverages.gva.cp.itl3.ukminuslondon <- gva.cp.itl3 %>%
rename(region_grouping = UK_minus_london) %>%
group_by(region_grouping,year) %>%
summarise(
weighted_mean_gva = weighted.mean(gva_per_capita, personcount, na.rm=T)#get weighted average by each ITL2 grouping
) %>% #merge in SY values
left_join(gva.cp.itl3 %>% filter(region == 'Sheffield') %>% ungroup() %>% select(year, Sheffield_gva = gva_per_capita), by = c('year')) %>%
left_join(gva.cp.itl3 %>% filter(grepl(x = region, pattern = 'Barnsley', ignore.case = T)) %>% ungroup() %>% select(year, BDR_gva = gva_per_capita), by = c('year'))
#Repeat for core cities exc Sheffield
weightedaverages.gva.cp.itl3.cores <- gva.cp.itl3 %>%
rename(region_grouping = core_cities_minus_sheffield) %>%
group_by(region_grouping,year) %>%
summarise(
weighted_mean_gva = weighted.mean(gva_per_capita, personcount, na.rm=T)#get weighted average by each ITL2 grouping
) %>% #merge in SY values
left_join(gva.cp.itl3 %>% filter(region == 'Sheffield') %>% ungroup() %>% select(year, Sheffield_gva = gva_per_capita), by = c('year')) %>%
left_join(gva.cp.itl3 %>% filter(grepl(x = region, pattern = 'Barnsley', ignore.case = T)) %>% ungroup() %>% select(year, BDR_gva = gva_per_capita), by = c('year'))
#Append those two
weightedavs.gva.cp.itl3 <- bind_rows(
weightedaverages.gva.cp.itl3.regions,
weightedaverages.gva.cp.itl3.ukminuslondon %>% filter(region_grouping!='London'),#London already in previous groupings
weightedaverages.gva.cp.itl3.cores %>% filter(region_grouping!='Other')
)
#Make Sheffield and BDR gva long, and find proportion diffs
weightedavs.gva.cp.itl3 <- weightedavs.gva.cp.itl3 %>%
pivot_longer(cols = Sheffield_gva:BDR_gva, names_to = 'place', values_to = 'gva') %>%
mutate(
prop_diff = (weighted_mean_gva - gva)/gva
) %>%
arrange(year) %>%
group_by(region_grouping,place) %>%
mutate(
prop_diff_3yrsmooth = rollapply(prop_diff,3,mean,align='center',fill=NA),
prop_diff_5yrsmooth = rollapply(prop_diff,5,mean,align='center',fill=NA),
)
#Factor order from previous plot
weightedavs.gva.cp.itl3$region_grouping <- factor(weightedavs.gva.cp.itl3$region_grouping, levels = levels(weightedavs.itl3$region_grouping))
#Plain prop diff looks smoothed already I think...
ggplot(weightedavs.gva.cp.itl3 %>% filter(region_grouping!='London'), aes(x = year, y = prop_diff * 100, colour = region_grouping)) +
# ggplot(weightedavs.gva.cp.itl3 %>% filter(region_grouping!='London'), aes(x = year, y = prop_diff * 100, colour = fct_reorder(region_grouping, prop_diff, .desc = T))) +
geom_line() +
geom_point(size = 2) +
coord_cartesian(ylim = c(-5,82)) +
geom_hline(yintercept = 0, alpha = 0.2, size = 2) +
facet_wrap(~place) +
scale_color_brewer(palette = 'Paired', direction = -1) +
ylab("Percent difference of... ") +
theme(legend.title=element_blank()) +
ggtitle("GVA per capita: Sheffield and Barnsley/Doncaster/Rotherham\nCompared to UK regions")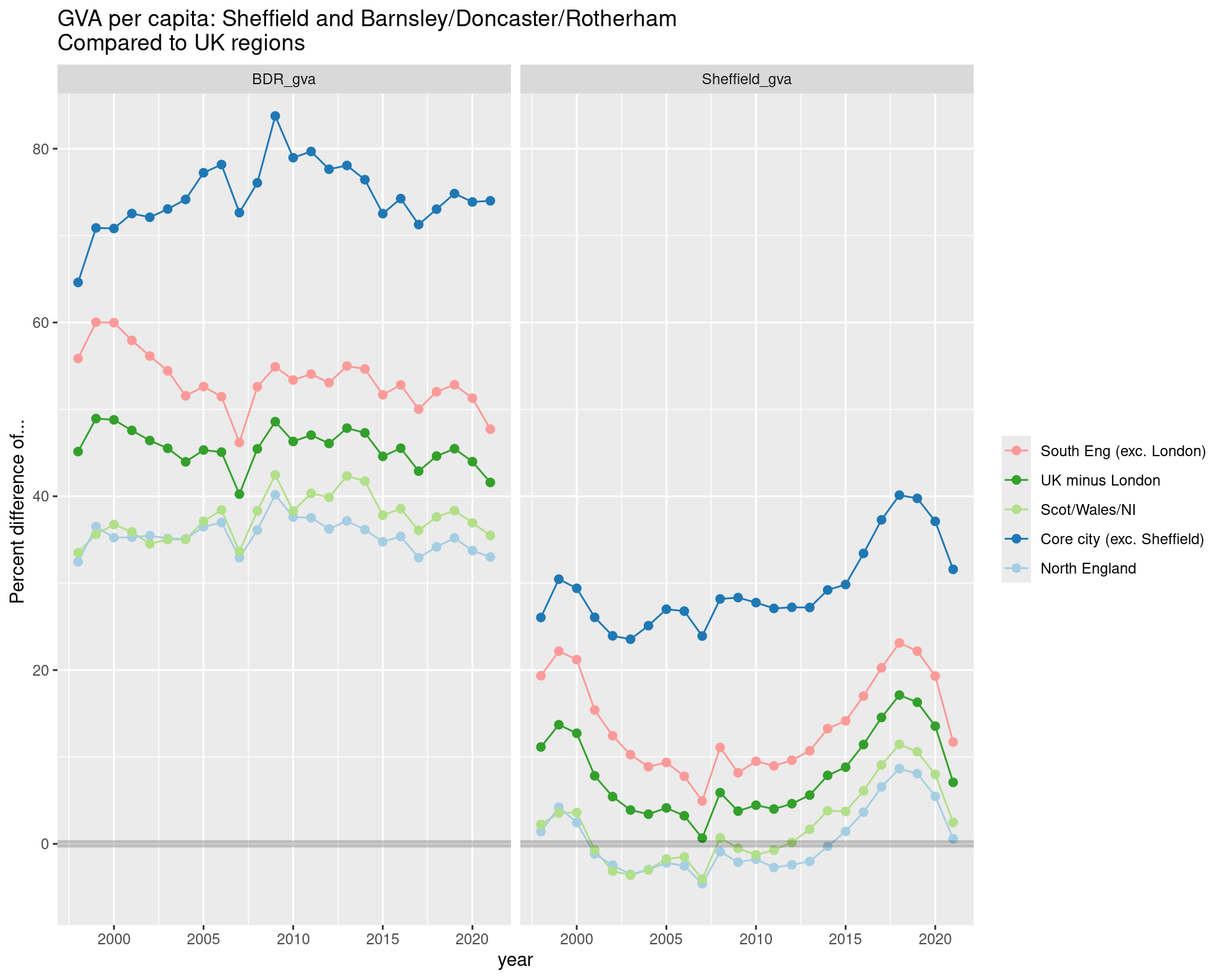
GVA per HOUR WORKED: Comparing Sheffield to other ‘core cities’
Sheffield has been fairly close to the middle of the pack for much of this history.
It looks like that changed more due to some places catching up rather than others pulling ahead.
But again: recent years, the gap has started to close again.
comparator = 'Sheffield'
# # comparator = 'Manchester'
# comparator = 'Leeds'
corecompare <- perhourworked.withtotalhours.itl3 %>%
select(region, year, gva) %>%
filter(region %in% corecities[corecities!=comparator]) %>%
left_join(
perhourworked.withtotalhours.itl3 %>%
filter(region ==comparator) %>%
select(year, sheffield_gva = gva),
by = 'year'
) %>%
mutate(prop_diff = (gva - sheffield_gva)/sheffield_gva) %>%
group_by(region) %>%
mutate(
prop_diff_3yrsmooth = rollapply(prop_diff,3,mean,align='center',fill=NA),
prop_diff_5yrsmooth = rollapply(prop_diff,5,mean,align='center',fill=NA),
)
#Keep factor for next plot
corecompare$region <- fct_reorder(corecompare$region, corecompare$prop_diff_3yrsmooth, .desc=T)
ggplot(corecompare, aes(x = year, y = prop_diff_3yrsmooth * 100, colour = region)) +
# ggplot(corecompare, aes(x = year, y = prop_diff_3yrsmooth * 100, colour = fct_reorder(region, prop_diff_3yrsmooth, .desc=T))) +
geom_line() +
geom_point(size = 2) +
coord_cartesian(ylim = c(-15,105)) +
geom_hline(yintercept = 0, alpha = 0.2, size = 2) +
scale_color_brewer(palette = 'Paired', direction = -1) +
ylab("Percent difference of... (3 year average)") +
theme(legend.title=element_blank()) +
ggtitle("Sheffield vs other 'core cities' GVA per hour worked:\n% difference of other core cities.")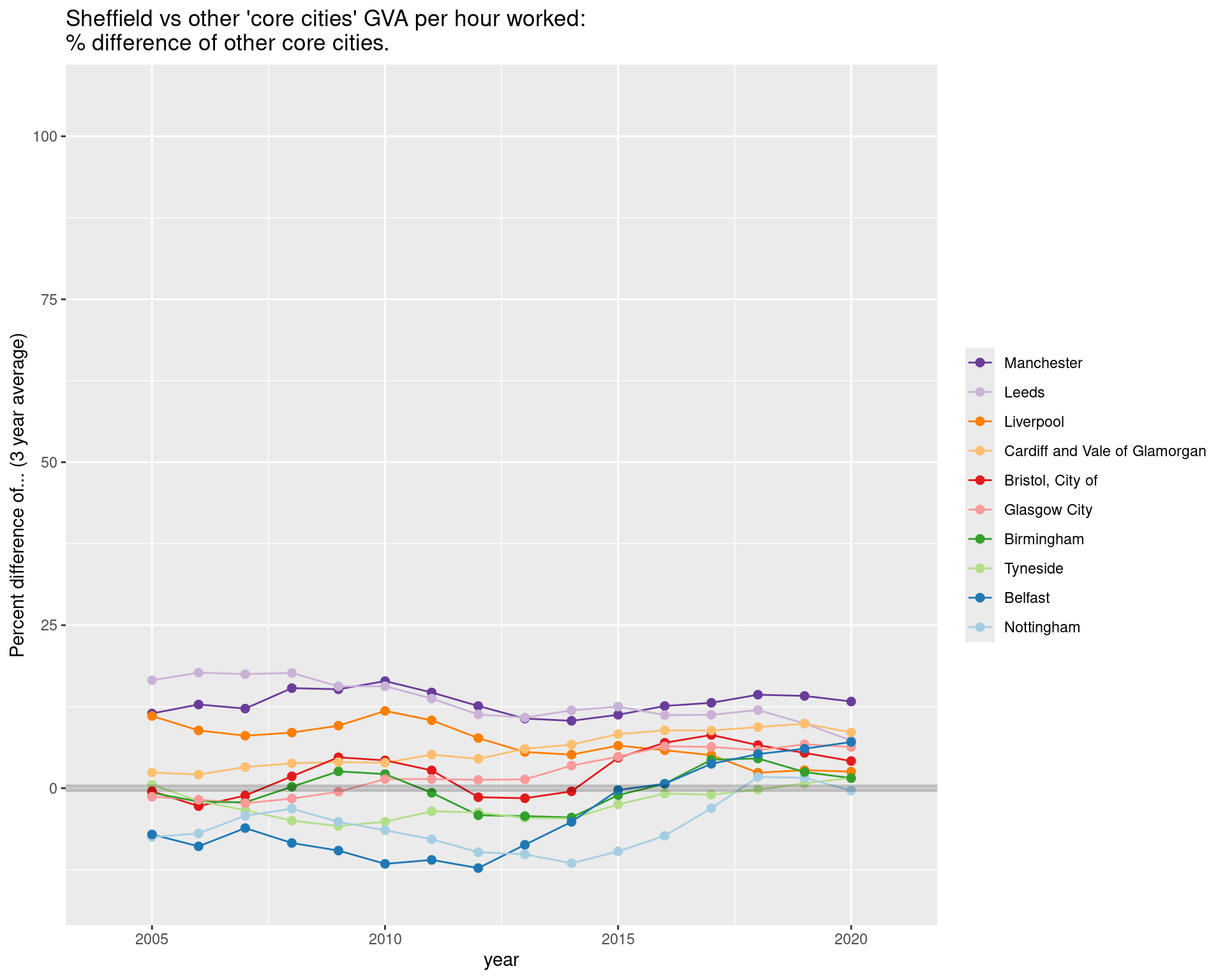
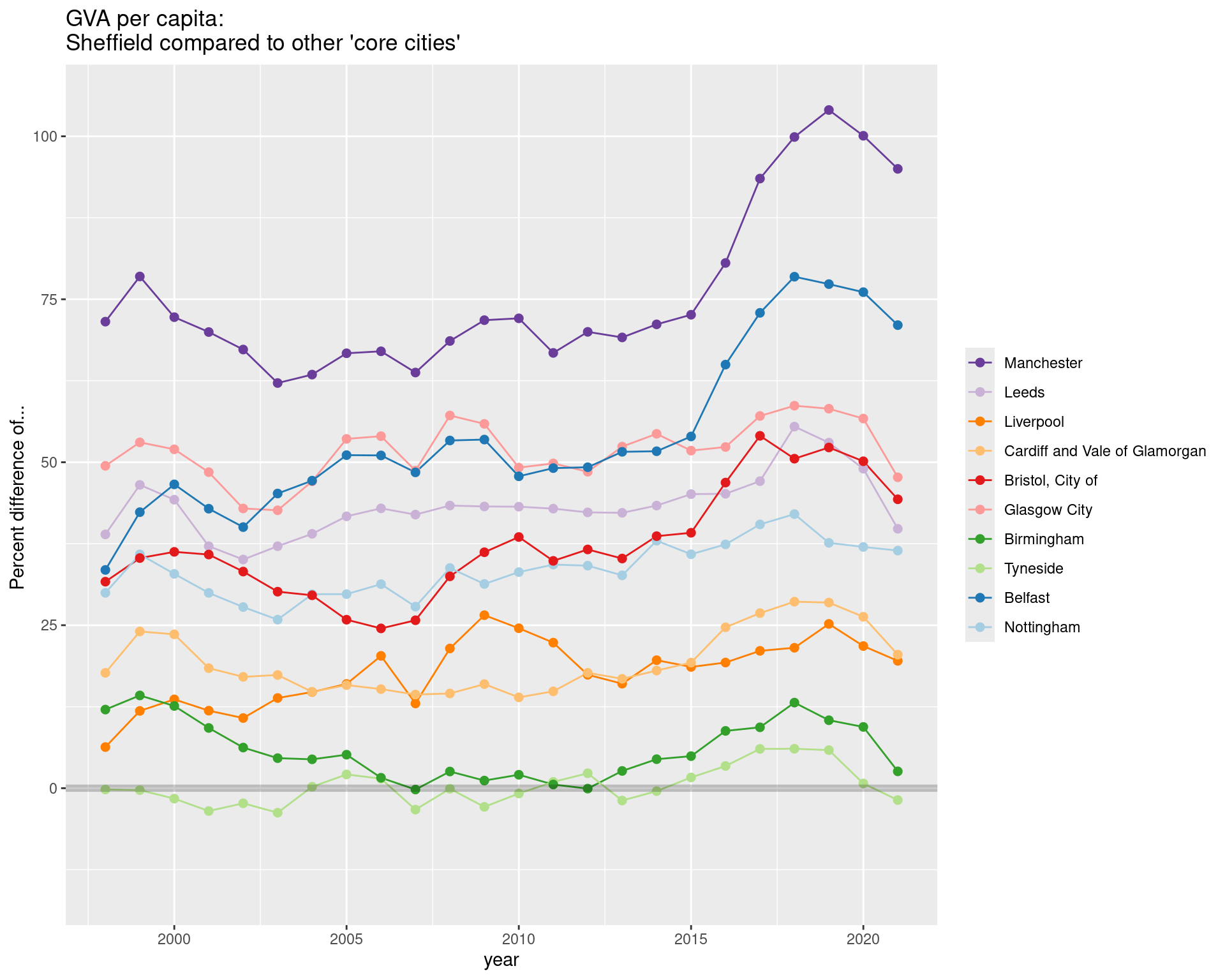
GVA per CAPITA: Comparing Sheffield to other ‘core cities’
For GVA per capita, Though the recent gap-closing is very visible, Sheffield is close to the lowest ranks when placed against the other ‘core cities’.
Around 2015, the opening of a gap to many others is very clear here.
Again: there are likely residential / commuter flow reasons for how much this differs from GVA per hour.
#VERSION TO DIRECTLY COMPARE SHEFFIELD TO OTHER 'CORE CITIES'
#Exclude Sheffield, as we want % diff for Sheffield, will add as own column
#Don't need hours per week as using direct GVA comparison, no need for weighted av
comparator = 'Sheffield'
# comparator = 'Manchester'
# comparator = 'Leeds'
# comparator = 'Nottingham'
corecompare.percapita <- gva.cp.itl3 %>%
select(region, year, gva_per_capita) %>%
filter(region %in% corecities[corecities!=comparator]) %>%
left_join(
gva.cp.itl3 %>%
ungroup() %>%
filter(region == comparator) %>%
select(year, sheffield_gva = gva_per_capita),
by = 'year'
) %>%
mutate(prop_diff = (gva_per_capita - sheffield_gva)/sheffield_gva) %>%
group_by(region) %>%
mutate(
prop_diff_3yrsmooth = rollapply(prop_diff,3,mean,align='center',fill=NA),
prop_diff_5yrsmooth = rollapply(prop_diff,5,mean,align='center',fill=NA),
)
corecompare.percapita$region <- factor(corecompare.percapita$region, levels = levels(corecompare$region))
ggplot(corecompare.percapita, aes(x = year, y = prop_diff * 100, colour = region)) +
geom_line() +
geom_point(size = 2) +
coord_cartesian(ylim = c(-15,105)) +
geom_hline(yintercept = 0, alpha = 0.2, size = 2) +
scale_color_brewer(palette = 'Paired', direction = -1) +
ylab("Percent difference of... ") +
theme(legend.title=element_blank()) +
ggtitle("GVA per capita:\nSheffield compared to other 'core cities'")